

How does AI think? In token-language
From Letters to Characters

What I know about language
Hi! I am a bilingual Singaporean who has been speaking chinese and english since childhood. These are two very different languages.
English spelling is easy to work out from phonetics and you only need to know 26 characters.
Chinese is a complicated language where even consulting the dictionary to figure out how to pronounce a character, is rather tough. We have ‘guess based off radicals’ and even a native speaker doesn’t necessarily know how to read other people’s names.

There are over 100,000 recorded Chinese characters in total (106,230 characters are recorded in Zhōnghuá zì hǎi dictionary) but to be considered literate, you just need to know 2000 to 8000 characters.
Still quite a lot. I will explain why.
English
You are reading this in English. I'm going to assume that you are rather familiar with this language, but here is a breakdown.
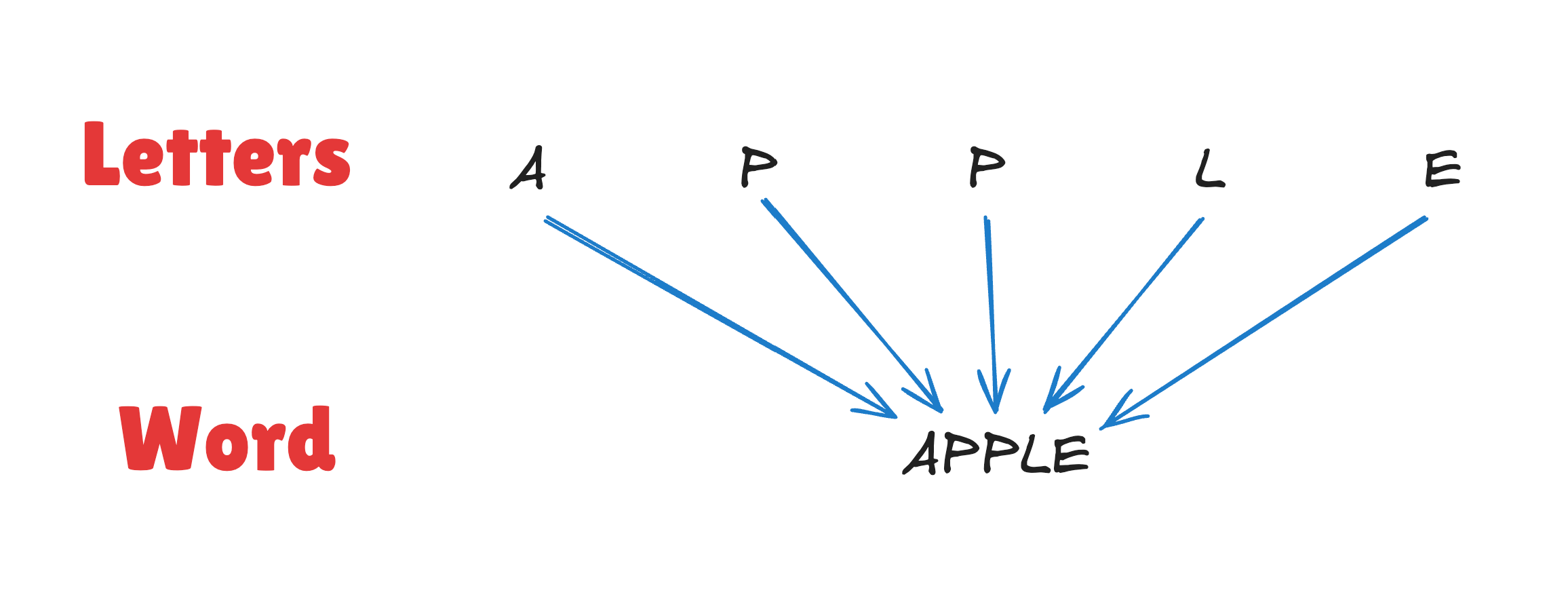
English is letter based. There are 26 letters forming the english alphabet, and those are reconfigured to form words. Each word is a unit of meaning.
The letters themselves don’t mean anything. They are small building blocks that are reused in different arrangements to form words. We have word boundaries marked by space and some punctuations to form a small symbol set.
Chinese
Chinese is character based. Each character is a different word, with a different meaning, and character-words combined together change the meaning further.
For example,
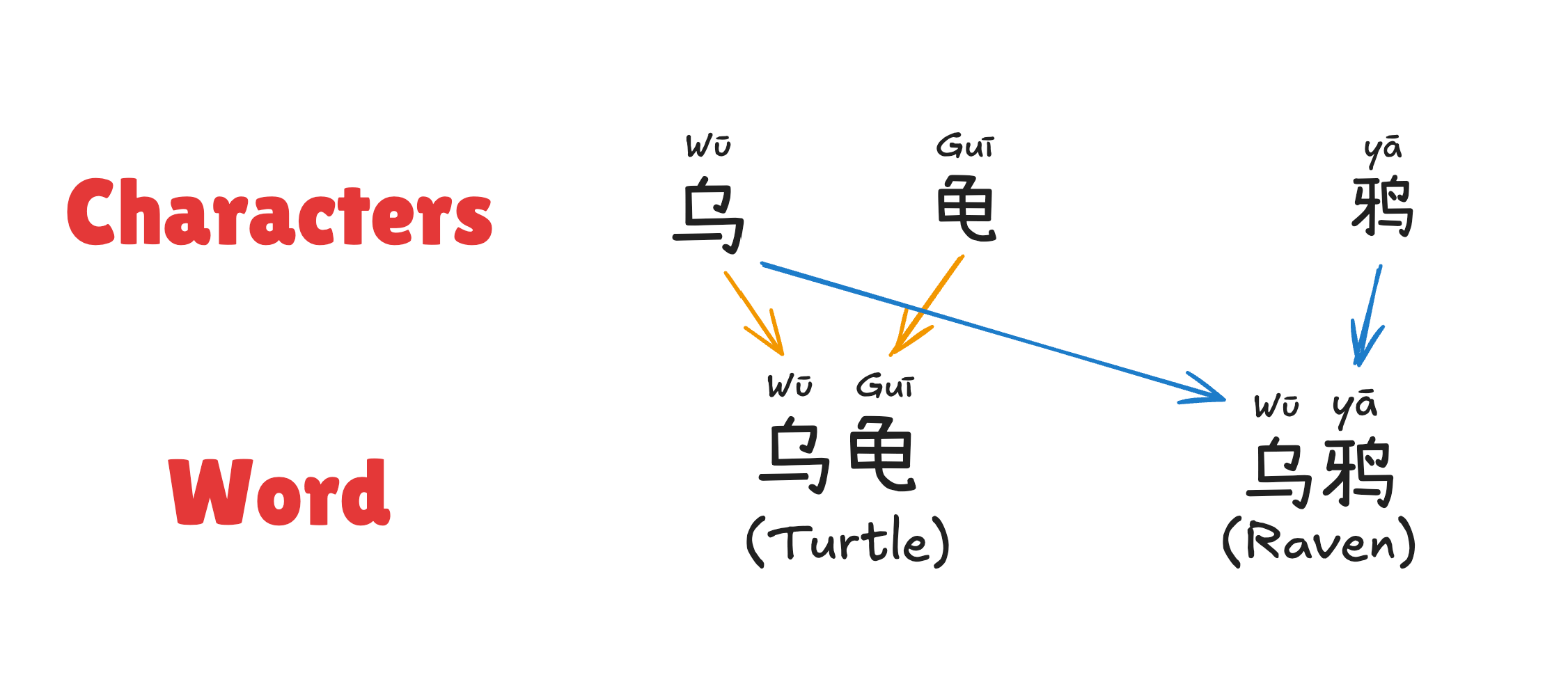
The characters themselves have a meaning and are usually derived from a pictogram, so the modern bird-shaped character 乌 (Wū) is a simplified form of the traditional character 烏 (Wū), which is a drawing of a crow turned into a character. This character means ‘Crow, Raven, Rook’ or ‘Black, Dark, Murky’ depending on how it is used.
The characters do not have to be combined, but they can be combined to change the meaning.
鸦 (yā) is ‘duck’ and a word on it’s own.
乌鸦 (Wū Yā) is a combined word-phrase for ‘raven’.
The characters can be decomposed into radicals, in the same way as the english alphabet.
“猫” means cat.
“狗” means dog.
You see how they both have the "犭" (quǎn) radical? This is known as the "beast radical" and it indicates that the character has something to do with animals.
This is not really how we form words in chinese writing. We could combine radicals to form the character, but it is more like assembling a puzzle than spelling out a word.
Summary of Chinese
There are no spaces between words in written Chinese.
Chinese characters can combine to form compound words, but each character already means something.
Chinese has a large symbol set (thousands of characters in common use).
A little background (About Me)
I have spent five years doing a PhD in MARL (Multi-Agent Reinforcement Learning), specifically working on how to train agents (think robot brains) to work together in teams.
My research is in the field of Artificial Intelligence (AI) & Machine Learning (ML), and even uses some of the same methods (Reinforcement Learning, where you train the agent with a reward function instead of giving it good and bad examples, you rate how good its behaviour is).
What I know about LLMs
I have also been playing with LLMs (Large Language Models, i.e Claude, ChatGPT, Google Gemini) since my graduation in 2025 (so for the last year), mostly at the functional power-user level instead of getting into the nitty-gritty of training an LLM.
I would say that I'm reasonably proficient in this area, if not doing full out research and writing papers. This blog is a learning log of me figuring out these things.
LLMs are prediction engines

The LLM essentially is given text (your question) and it predicts what is the most likely word, that should come out next, repeatedly, forming the answer to your question.
This is why when you send a question to ChatGPT, it streams the answer to you word by word. Because the LLM is doing its best to predict the next best word, that you want to see.
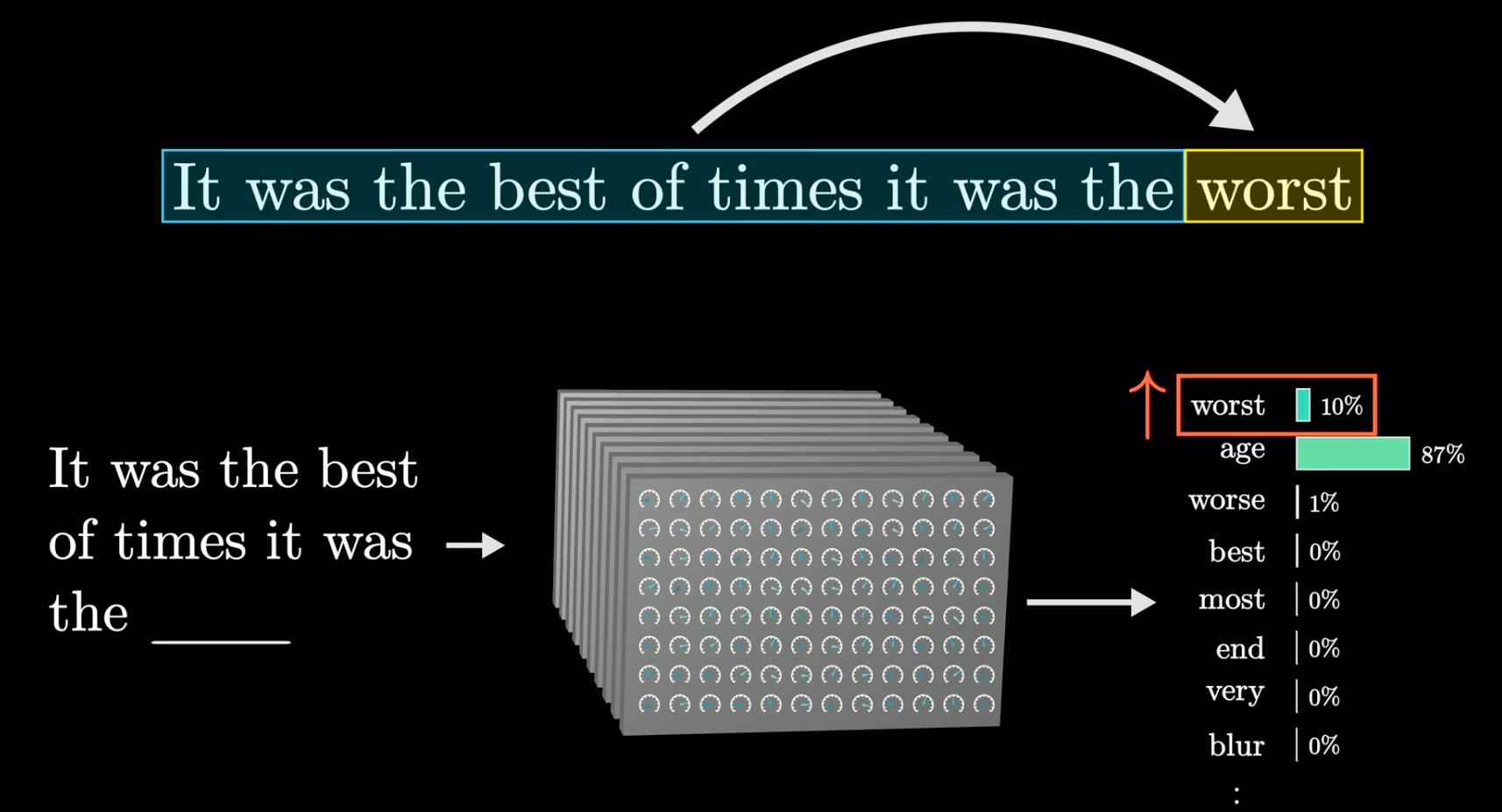
I recommend checking out this 8 minute video if you have patience for a full explanation. This is the ‘prediction of next word’ in action, you can see on the bottom right, the various next word options and the probability of seeing each word, depending on the sentence that came before it.
This is also why there are problems of AI accuracy, people complaining that AI is lying to them and a lot of AI slop that doesn’t really make sense if you think about it. The AI is doing pattern prediction, based off its training data, which is text people have written after they reasoned something through.
They can follow the patterns to get something that looks like other texts they have seen before, but it is not necessarily ‘correct’. It is just ‘similar to other texts’.
AI accuracy is not the focus of this article, but I did just have to explain to my aunt who wanted to use AI in her work with guiding the elderly. I feel like most people are struggling to understand AI sycophancy and inaccuracy despite being given the correct data.
I’m not saying its useless. We know it can generate rather good results. Not always perfect, but helpful for things such as making summaries and daily reviews.
Absolutely amazing for coding too.
I am not big on OpenClaw & Hermes Agent which go into ‘personal assistant agents’ because I rather not spend most of my time maintaining these, and it gets fiddly if you try to combine too many features in. But agentic coding is bringin a whole new age of coding + personal software development.
The Question
Back to the topic!
So when an LLM “predicts the next word,” what is it actually predicting?
What do AI learn to output? A word? A letter? A character?
English builds words from a small alphabet (26 letters). Chinese uses thousands of distinct characters where each one carries its own meaning.
What happens when we are predicting for a language that has so many characters?
What we're trying to figure out here is how does AI think in multiple languages? How does this prediction-thinking work?
How does AI Read?
LLMs don’t generate words OR letters. They generate tokens.
LLMs don’t read text the way humans do. They don’t see letters or words as distinct units. Instead, they convert text into tokens.
The model’s job is: given a sequence of tokens so far, predict the probability distribution over the next token.
So it doesn’t need to care about the language. It just needs to focus on the pattern prediction. E.g. blue token always has a higher chance of coming after the yellow token.
What are tokens?
A token is an arbitrary chunk of text, determined by the tokenizer.
The tokenizer is a lookup table that maps text chunks to integer IDs, and those IDs are what the model actually works with.
A token could be:
A whole common word: “understanding” → token #3314
Part of a word: “supercalifragilistic” → “super” + “cali” + “fragi” + “listic”
A single letter: “a” → token #64
A single Chinese character: “的” → token #23479
Part of a Chinese character (Radicals): “猫” → token #48213 + token #51007
The tokenizer decides all of this before the model sees anything.
How do we decide the mappings?
The tokenizers are built from training data using frequency analysis.
The most common algorithm is Byte-Pair Encoding (BPE). It works like this:
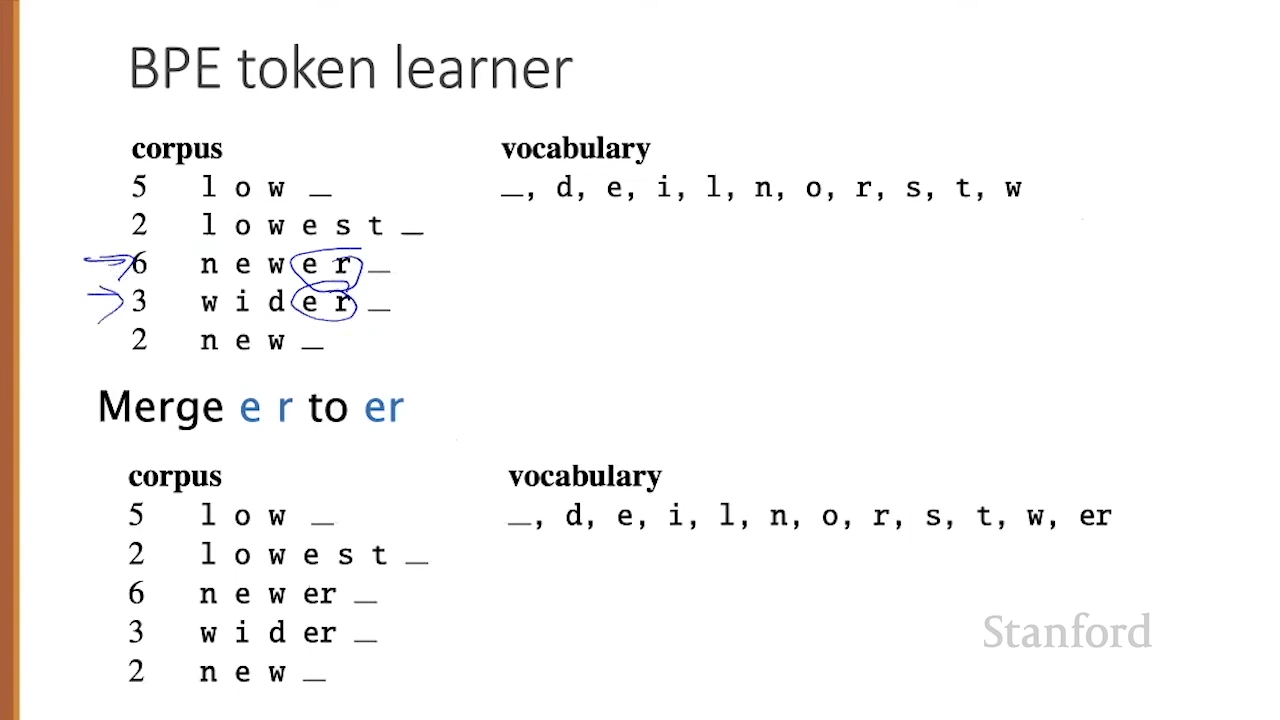
Start with individual bytes/characters as tokens (e.g. the alphabet)
Count how often each pair of tokens appears next to each other in the training data
Merge the most frequent pair into a new single token
Repeat thousands of times until you reach your target vocabulary size
The more complicated combined tokens are essentially like shortcuts, so the model can spend less tokens to generate the same prediction.
Common English words become single tokens:
“the” → 1 token
“understanding” → 1 token (it’s common enough)
“supercalifragilistic” → probably 3-4 tokens
Average: roughly 1 token per 4 English characters, or about 0.75 tokens per English word.
A single Chinese character often gets split into 2-3 tokens because many early tokenizers were trained mostly on English-dominated data (e.g. GPT-2), so Chinese characters are “rare” and don’t get merged into single tokens
Average: roughly 2-3 tokens per Chinese character
GPT-2 tokenizes Chinese at roughly 2-3x the token cost of English for equivalent meaning. So for the same semantic content, Chinese text can use 2-5x more tokens than English.
This means a Chinese sentence eats through the context window much faster
Problem: The multilingual tax
What gets tokens merged depends entirely on what’s common in the training data.
Why this matters:
Cost
If you’re paying per token (which most APIs do), Chinese costs 2-3x more than English for the same content.
Context window squeeze
A model with 4K context tokens can hold roughly 4K English words of meaning, but maybe only 1.5-2K Chinese “words” (characters) of meaning. You’re paying the same token budget but getting less semantic content through.
Training data bias
Most LLMs are trained on data that is predominantly English. This means:
The tokenizer was optimized for English, not Chinese
The model saw less Chinese during training
The model has fewer parameters dedicated to Chinese patterns
Chinese output quality suffers as a compound effect
This is sometimes called “tokenization parity” or the “multilingual tax”.
Character splitting breaks meaning
When a single Chinese character gets split across multiple tokens, the model has to learn to reassemble the meaning across token boundaries. This is extra work that English doesn’t require. It’s like if you had to process “understanding” as “un” + “der” + “stan” + “ding” every time instead of recognizing it as one unit. Chinese-specific models (like those from Alibaba, Baidu, or models trained on predominantly Chinese data) build tokenizers that treat whole Chinese characters as single tokens, which fixes most of these problems. But they then have worse English performance.
This isn’t just a chinese problem, the same pattern applies to many non-Latin-script languages:
Japanese (mix of kanji, hiragana, katakana) faces similar token inflation
Korean (Hangul) depends on whether the tokenizer learned syllable blocks
Arabic, Hindi, Thai, and others all face token penalties in English-first tokenizers
Solution: We have different tokenizers
Newer models and tokenizers are improving:
Chinese-specific LLMs (Qwen, Yi, ChatGLM) use tokenizers optimized for Chinese, achieving ~1.3-1.5 tokens per character instead of 2-3
Multilingual tokenizers (like Llama 2/3, GPT-4’s tokenizer) include more Chinese characters in the vocabulary, reducing the per-character token count.

In a nutshell
AI models can respond in different languages because they are never reading that language. They are looking at abstract token prediction. Which is really pretty hard.
Larger vocabulary size = more difficult to train.
If you give a robot 4 actions, it can build a decent model of what to do in that environment with 20 hours of training.
If you give a robot 2000 actions, it may need to train for the next decade to get enough experience to figure out what it should do.